
Recall Fidelity in the Age of Generative Engines
1. Introduction: The Generative Recall Challenge
Generative engines now mediate the majority of AI-powered information queries, shifting from ranked retrieval to synthesized answers. In this paradigm, sources are often paraphrased, reframed, or omitted entirely, leading to a new class of visibility risk: degraded recall. Unlike classical search, where inclusion implied presence, generative systems compress and abstract information — sometimes introducing hallucinations or misattributions.
Recent benchmarking from Vectara's Hallucination Evaluation Leaderboard (2025) illustrates the variance in hallucination rates among popular answer engine models:
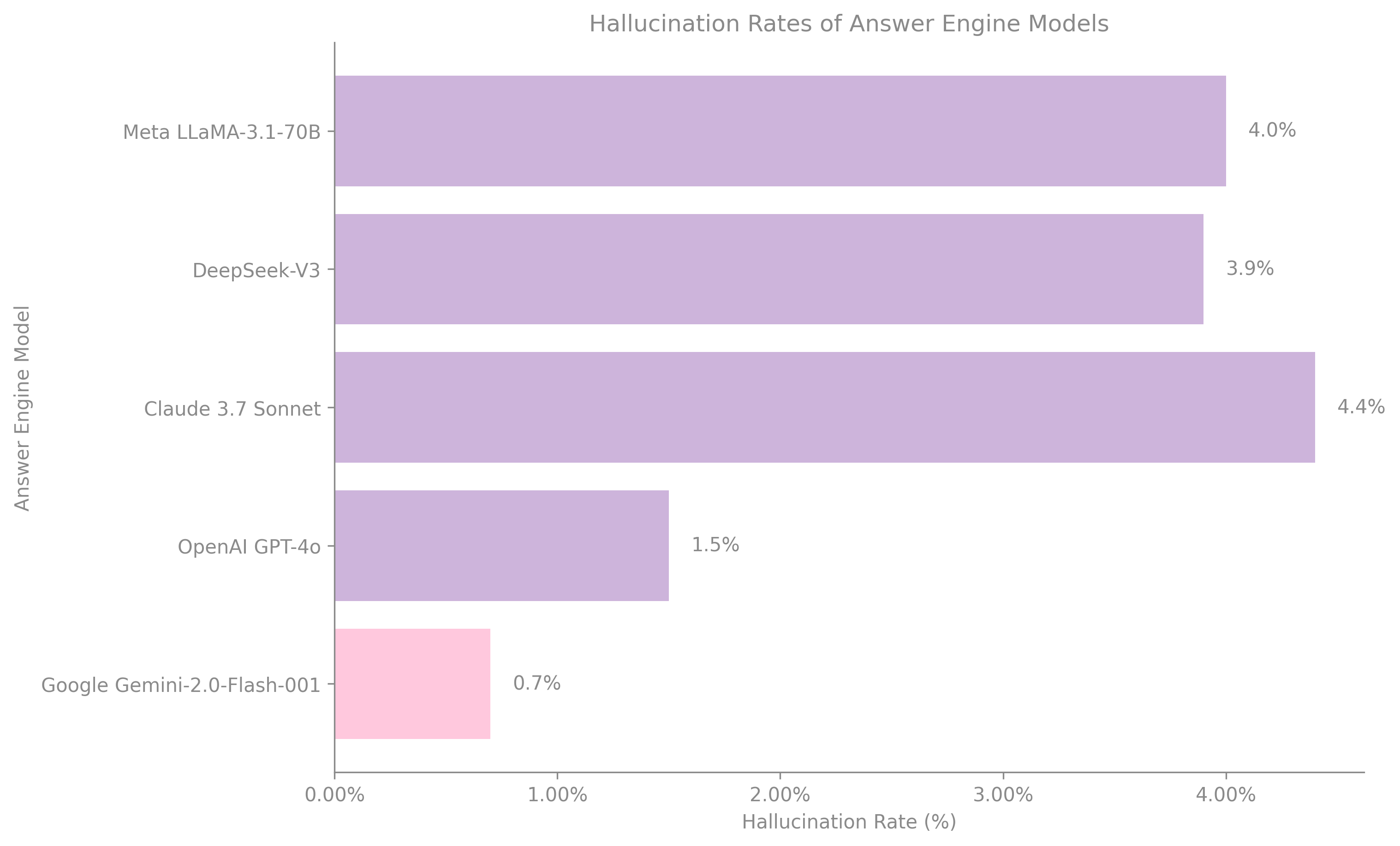
Hallucination Rates of Answer Engine Models
Compares the hallucination rates of different answer engine models based on Vectara's Hallucination Evaluation Leaderboard (2025). A lower bar indicates better performance.
- Google Gemini-2.0-Flash-001: 0.7% hallucination rate, 99.3% factual consistency
- OpenAI GPT-4o: 1.5% hallucination rate, 98.5% factual consistency
- Claude 3.7 Sonnet: 4.4% hallucination rate, 95.6% factual consistency
- DeepSeek-V3: 3.9% hallucination rate, 96.1% factual consistency
- Meta LLaMA-3.1-70B: 4.0% hallucination rate, 95.9% factual consistency
These results demonstrate that while top-tier models outperform predecessors, hallucination and citation drift still occur even in high-performing systems. Thus, visibility in generative contexts demands engineered observability and content-level intervention.
2. Defining Recall Fidelity and Drift Types
We define recall fidelity as the likelihood that a model retrieves and regenerates a specific knowledge unit with correct attribution and preserved context. It operates on four primary axes:
| Layer | Description |
|---|---|
| Retrievability | Can the model access the source via internal weights or external RAG? |
| Attribution | Is the original source properly credited or cited? |
| Framing Integrity | Is the original context (intent, scope, limitations) preserved? |
| Temporal Validity | Is the information still accurate within its intended time window? |
Drift Types:
- Lexical Drift
The content is paraphrased in a way that reduces precision.
- Attribution Drift
The citation is omitted, generalized, or misassigned.
- Semantic Drift
The meaning of the original claim is altered or contradicted.
These forms of degradation threaten the factual integrity and traceability of generative outputs.
3. Observability Through Prompt Probing and Monitoring
To monitor recall fidelity, we introduce a probing protocol:
- Define a set of canonical knowledge units (e.g., 'The ROI of coaching is 7x according to ICF').
- Create 2–3 natural language prompt variants per knowledge unit.
- Query selected LLMs (e.g., GPT-4o, Claude 3.7, Gemini) at regular intervals.
Example Probe Log Entry:
prompt: "What is the average ROI of leadership coaching?" model: "GPT-4o" response: "Some experts say coaching has a 5x to 8x ROI." retrievability: pass attribution: partial framing: pass temporal_validity: pass drift_detected: attribution_drift
This framework enables structured monitoring and can be scaled using tools like LangChain, PromptLayer, or custom logging pipelines.
4. Corrective Feedback Loops and Optimization Strategies
Once drift is detected, corrective actions should follow a structured loop:
- Content Refresh
Update or clarify the source page.
- Structured Data Enhancement
Add schema.org markup to increase machine readability.
- Index Pinging
Use protocols like IndexNow to notify engines of updates.
- Embedding Refresh
Recompute vector embeddings in RAG systems.
- Feedback Submission
Leverage OpenAI, Anthropic, or Gemini feedback APIs.

Corrective Feedback Loop for Recall Fidelity
Illustrates the iterative process of addressing recall drift, from detection to corrective actions and feedback loops.
Studies and platform documentation (SchemaApp, CMSWire, 2024–2025) affirm that structured markup improves LLM comprehension and retrieval alignment.
5. Conclusion
LLMs do not recall uniformly. Recall fidelity must be engineered. Organizations seeking durable visibility in AI interfaces must go beyond traditional SEO and adopt recall-centric optimization. This includes structured content, monitoring tools, prompt benchmarking, and model feedback. As AI-generated answers become a dominant interface for knowledge access, citation transparency, fidelity tracking, and contribution to open standards will be key to information integrity.
Key Insights
Even top AI models like Gemini (0.7%) and GPT-4o (1.5%) still produce hallucinations, requiring content optimization strategies
Structured data markup (schema.org) significantly improves LLM comprehension and retrieval alignment
Content refreshes, index pinging, and feedback APIs are essential corrective measures to maintain visibility in AI responses
References
- 1. Ji, Z., et al. (2023). A Survey on Hallucination in Large Language Models. arXiv:2305.17888. https://arxiv.org/abs/2305.17888
- 2. Guo, B., et al. (2024). An Empirical Study on Factuality Hallucination in Large Language Models. arXiv:2401.03205. https://arxiv.org/abs/2401.03205
- 3. Liu, J., et al. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997. https://arxiv.org/abs/2312.10997
- 4. Zhou, Q., et al. (2024). Temporally Consistent Factuality Probing for LLMs. arXiv:2409.14065. https://arxiv.org/abs/2409.14065
- 5. Wang, Y., et al. (2024). Factuality of Large Language Models. EMNLP 2024. arXiv:2402.02420. https://arxiv.org/abs/2402.02420
- 6. Maheshwari, H., Tenneti, S., & Nakkiran, A. (2025). CiteFix: Enhancing RAG Accuracy Through Post-Processing. arXiv:2504.15629. https://arxiv.org/abs/2504.15629
- 7. Vectara. (2025). Hallucination Evaluation Leaderboard. Hugging Face Spaces. https://huggingface.co/spaces/vectara/Hallucination-evaluation-leaderboard
- 8. Dehal, R. S., Sharma, M., & Rajabi, E. (2025). Knowledge graphs and their reciprocal relationship with large language models. Machine Learning and Knowledge Extraction, 7(2), 38. https://doi.org/10.3390/make7020038